阅读容器的源码,然后读到了一些有意思的东西。
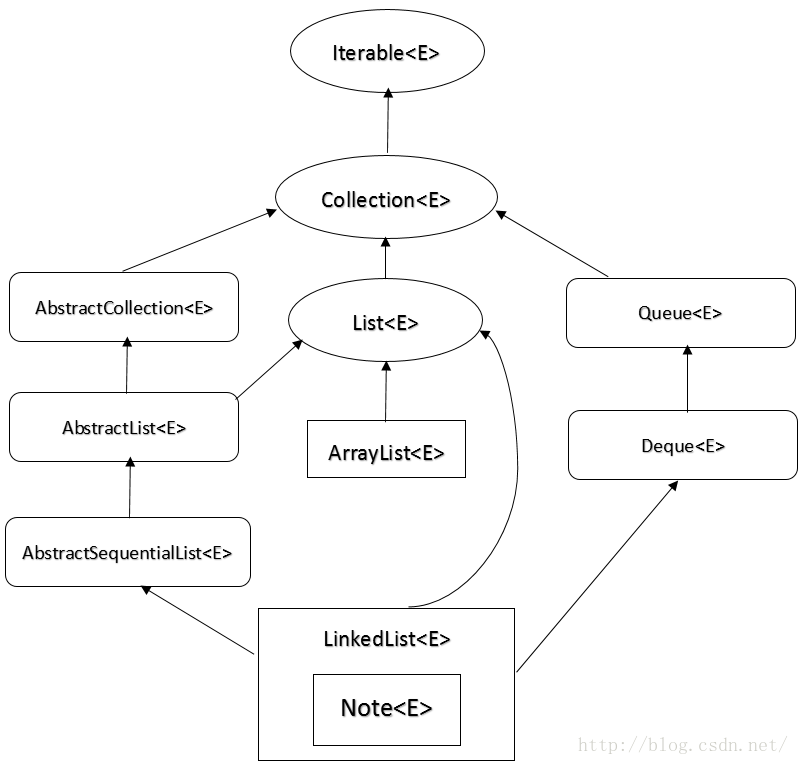
LinkedList&ArrayList的底层关系 先从两个链表的底层实现看,LinkedList是通过继承AbstractSequentialList这个抽象类,实现List、Deque、接口实现的,而ArrayList是直接通过List实现的,所以,从底层实现看,LinkedList实现要更加复杂。
底层的实现 在ArrayList类的内部,ArrayList构建了一个默认数组,对于有参构造器数组的长度默认为10,对于无参构造器ArrayList构造了一个默认的空的数组来进行实现。
ArrayList的扩容 ArrayList通过一个数组来进行实现,那么数组的优点是能够快速的进行数据检索,但是插入和删除相较Linkedlist更加困难,除此之外,数组的特性也决定了扩容一个数组是非常困难的,然后阅读了一下源码内对于扩容的实现方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 public void ensureCapacity(int minCapacity) { if (minCapacity > elementData.length && !(elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA && minCapacity <= DEFAULT_CAPACITY)) { modCount++; grow(minCapacity); } } private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8; private Object[] grow(int minCapacity) { return elementData = Arrays.copyOf(elementData, newCapacity(minCapacity)); } private Object[] grow() { return grow(size + 1); } private int newCapacity(int minCapacity) { // overflow-conscious code int oldCapacity = elementData.length; int newCapacity = oldCapacity + (oldCapacity >> 1); if (newCapacity - minCapacity <= 0) { if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) return Math.max(DEFAULT_CAPACITY, minCapacity); if (minCapacity < 0) // overflow throw new OutOfMemoryError(); return minCapacity; } return (newCapacity - MAX_ARRAY_SIZE <= 0) ? newCapacity : hugeCapacity(minCapacity); } private static int hugeCapacity(int minCapacity) { if (minCapacity < 0) // overflow throw new OutOfMemoryError(); return (minCapacity > MAX_ARRAY_SIZE) ? Integer.MAX_VALUE : MAX_ARRAY_SIZE; }
能够看到,ArrayList建立一个新的数组,这个数组的容量通过移位运算扩展为现在数组的1.5倍,然后将原数组复制到新数组之中,在将引用转向原数组来实现扩容。
1 2 3 4 5 6 7 8 9 10 11 12 13 public void add(int index, E element) { rangeCheckForAdd(index); modCount++; final int s; Object[] elementData; if ((s = size) == (elementData = this.elementData).length) elementData = grow(); System.arraycopy(elementData, index, elementData, index + 1, s - index); elementData[index] = element; size = s + 1; }
在实际使用过程中,即添加一个新项,但是新项超出数组上限,然后调用方法进行数组扩容。
LinkedList的实现-双链表 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 Linkedlist实现: transient int size = 0; transient Node<E> first; transient Node<E> last; private static class Node<E> { E item; Node<E> next; Node<E> prev; Node(Node<E> prev, E element, Node<E> next) { this.item = element; this.next = next; this.prev = prev; } }
通过阅读源码,能够看到JDK对于LInkedlist的实现是采用了一个双链表,那么问题来了,为什么不采用单链表?我没有能够查找到相关信息,但是通过阅读源码,我发现Linkedlist在查找某一个结点的过程中是通过一种类似于折半查找的方法来进行查找,为什么说类似,是因为这种二分查找只进行一次,也就是在得到结点的位置的时候,通过比较位置的大小和链表的长度,来确定查找的范围。所以,能够推测,在整个链表的查找中,运用这种类似的前后方向不同的查找,所以,Linkedlist采用了双链表作为实现方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 Linkedlist查找结点的方法: Node<E> node(int index) { if (index < (size >> 1)) { Node<E> x = first; for (int i = 0; i < index; i++) x = x.next; return x; } else { Node<E> x = last; for (int i = size - 1; i > index; i--) x = x.prev; return x; } }