同步语义-synchronized+final
Java中的锁–synchronized
在并发编程中,synchronized一直是非常重要的角色。通过加锁解锁,让临界区互斥执行,并且释放一个锁的线程向获取同一个锁的线程发送消息。
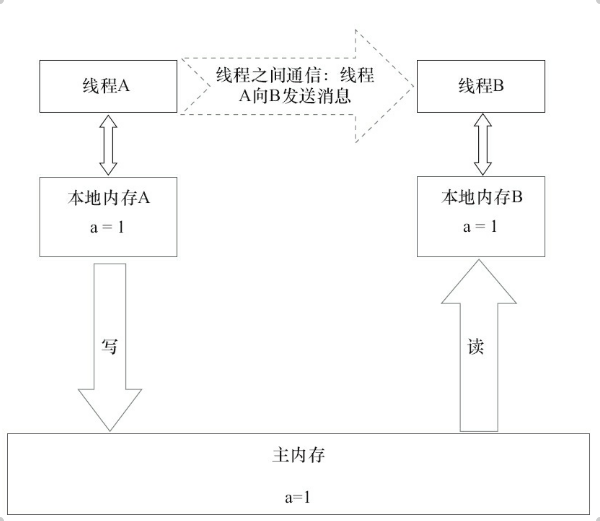
在上面的示意图中,A线程先进行加锁,然后更新a的值,A释放锁之后,线程A会把a的值刷回到主内存中,当B进行加锁的时候,会从主内存中重新读取数据,此时就拿到了最新的A改变的a的值,也就是在两个线程中间做到了通信。锁的这种通信方式也是JMM所采用的共享内存模型。
在JDK1.6之后,对synchronized的语义进行了优化,让这个锁变的没有那么重量级了。
锁的优化
在Java 1.6之后,在Java中,并发的锁有了四种状态:无锁状态、偏向锁、轻量级锁、重量级锁。
在JMM的实现中,无锁状态指的是采用了CAS(CompareAndSet)算法对共享变量进行操作。
CAS
在每次对共享数据进行刷新的时候,传入内存值,旧的预期值和要修改的值,当且仅当内存值和旧的预期值相同时,将这个值修改为要修改的值,否则返回错误。
缺陷
ABA问题。即如果存在两个线程T1和T2,T1使用CAS进行检查,在这期间,T2将数据A先修改到B,再将数据修改回A,T1检查数据是正确的,但是实际上数值已经被修改。
循环时间长开销大。
只能保证一个共享变量的原子操作。
三种锁的优劣:
| 锁 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 偏向锁 | 加锁和解锁不需要额外的消耗,和执行非同步方法相比仅存在纳米级的消耗的差距 | 如果线程中存在锁竞争,会带来额外的锁撤销的消耗 | 适用于只有一个线程访问同步块的场景。 |
| 轻量级锁 | 竞争的线程不会阻塞,提高了程序的响应速度 | 如果始终得不到锁竞争的线程,使用自旋会消耗CPU | 追求响应时间;同步块执行速度非常快 |
| 重量级锁 | 线程竞争不使用自旋,不会消耗CPU | 线程阻塞,响应时间缓慢 | 追求吞吐量;同步块执行速度较长 |
synchronized在执行互斥代码时的步骤
获得互斥锁
清空工作内存
拷贝变量的最新副本到工作内存
执行代码
将更改后的变量的值刷新到主内存
释放锁
final语义规则
对final域,在编译器和处理器之间遵循两个重排序规则:
在构造函数内对一个final域的写入,与随后把这个构造对象的引用赋值给一个引用变量,这两个操作之间不能重排序。
初次读一个包含final域的对象的引用,与随后初次读这个final域,这两个操作之间不能重排序。
写final域的重排序规则
JMM禁止编译器把final域的写重排序到构造函数之外。
编译器会在final域的写之后,构造函数return之前,插入StoreStore屏障。这个屏障禁止处理器把final域的写重排序到构造函数之外。
通过上述两个写域的规则,JMM能够确保在对象引用为任意线程可见之前,对象的final域已经被正确初始化过了,也就是另外一个线程读到的final域的数据一定是期望的值。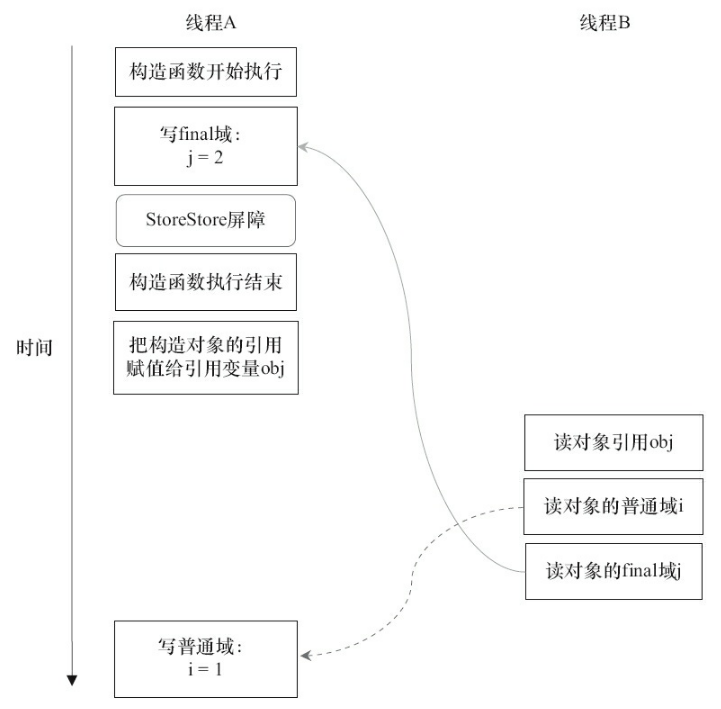
读final域的重排序规则
在读final域之前,编译器会在操作前面插入一个LoadLoad屏障。通过这个屏障,JMM可以确保在读一个final域之前,一定会先读包含这个final域的对象的引用。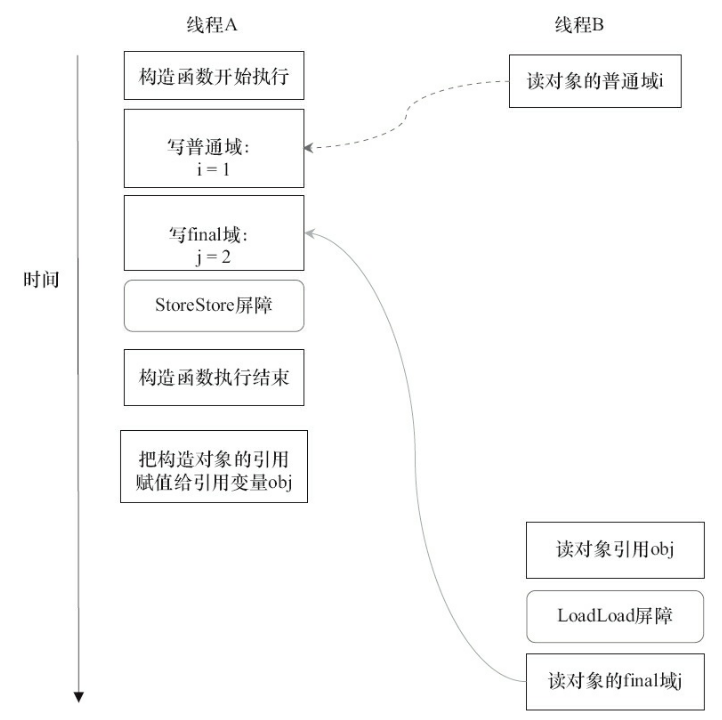
this逸出
在执行对象的构造过程的时候,会存在一种诡异的现象:this逸出。也就是在对象构造过程中,对象的引用在对象未能够构造完成的情况下引用被赋值给其他线程。
1 | public class FinalReferenceEscapeExample { |
在上述代码中,当有两个线程A执行的writer()时候,在构造函数内部,如果发生重排序,即对象赋值先于final初始化发生,并且在这个过程中,线程B执行reader()方法,那么读取到的obj将是已经不为null的对象,接着读取到未初始化的final域i,发生错误。
所以在函数构造过程中,要保证在构造函数返回前,被构造对象的引用不能够被其他线程看见。